Polling Home Assistant to store data long term
I have been running Home Assistant for a few years now. It is great at automating my house, but the built-in history is not really meant for long term analytics. I wanted sensor data in a database where I could query it properly, keep useful history, and build Grafana dashboards without depending on Home Assistant’s recorder database.
I recently released the project on GitHub: acaylor/hass-poller.
This is a Go service that polls Home Assistant, filters the entities I care about, and writes numeric state changes to PostgreSQL with TimescaleDB enabled. It is not a groundbreaking idea, but it is exactly the sort of private homelab utility I would probably not have time to build without AI tools. I had been running it privately at home, and I finally cleaned it up enough that someone else could clone it and run it without first deleting all of my house-specific settings.
Why I built it
Home Assistant already stores history, but I wanted something a little more purpose built for long term metrics:
- Raw sensor readings for recent troubleshooting
- Hourly rollups for medium term dashboards
- Daily rollups that can be kept indefinitely
- A schema I can query directly from Grafana
- A small service that is easy to run with containers
The service polls Home Assistant API /api/states on a schedule, applies allowlist and blocklist patterns, skips non-numeric values, and writes a new row only when a value changes enough to matter. That last part keeps noisy sensors from generating rows forever just because a temperature value moved from 21.00 to 21.01.
The current storage model is:
- Raw measurements retained for 90 days
- Hourly aggregate retained for 1 year
- Daily aggregate retained indefinitely
That gives me detailed data when I am troubleshooting something recent and still preserves the long term trend data I actually want to keep.
The project
The repo includes the poller, database schema, Dockerfile, docker-compose.yml, and an example .env file. The quick start is meant to be normal Docker Compose:
cp .env.example .env
docker compose upThe important settings live in .env, including the Home Assistant URL and token, PostgreSQL credentials, poll interval, allowed entities, blocked entities, and per-entity epsilon overrides.
A simple allowlist might look like this:
HA_ALLOWLIST=sensor.*,binary_sensor.*
HA_BLOCKLIST=sensor.energy_*,sensor.uptimeThe broad include keeps the config short, and the blocklist cuts out the sensors that are too noisy or not useful for my dashboards.
The project also has a short architecture document in the repo that covers the components, data flow, filtering behavior, storage tiers, and failure modes: docs/ARCHITECTURE.md.
Running at home
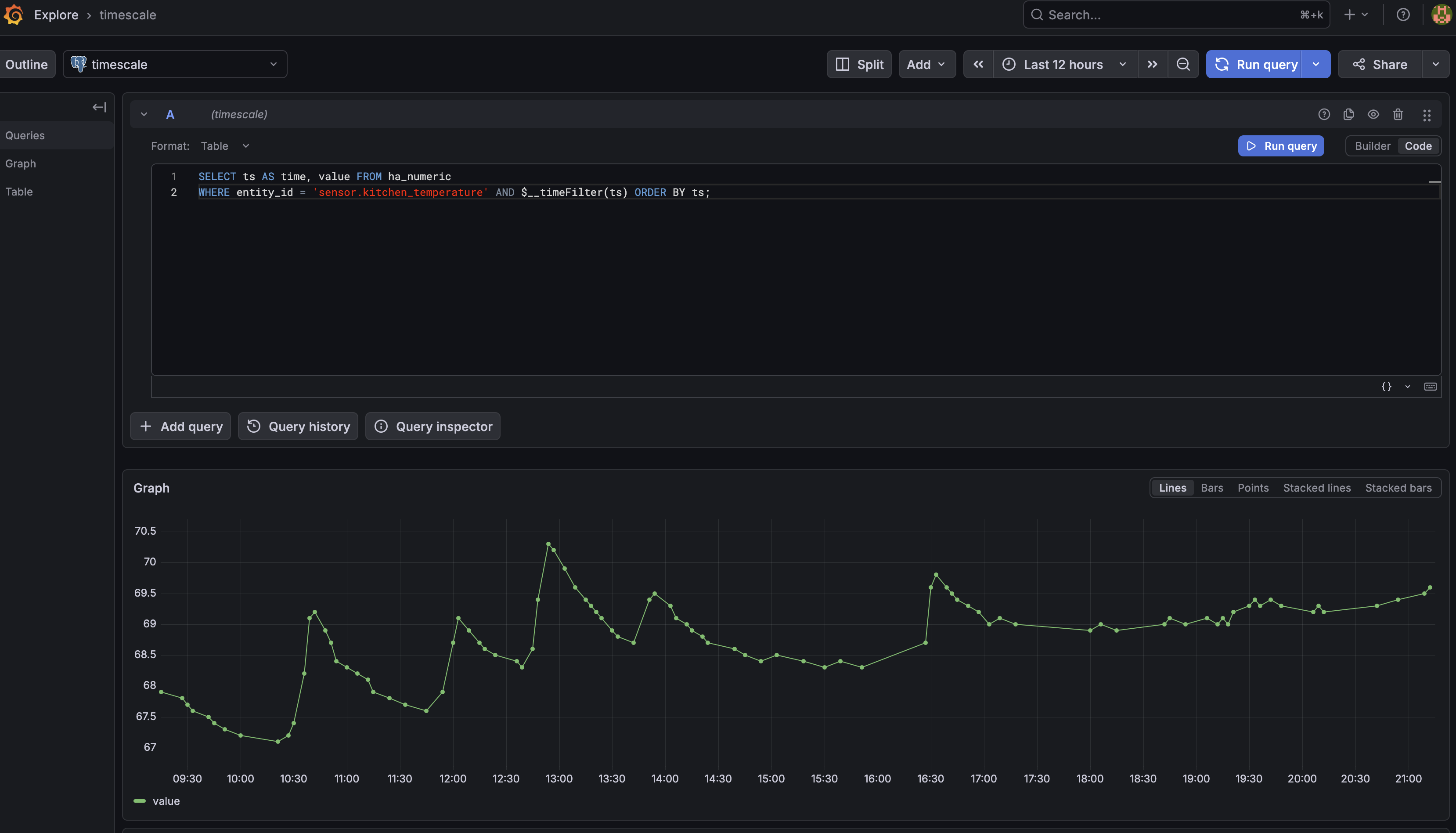
I do not have a frontend for this project. The database is the interface. Grafana already supports PostgreSQL, so I can point Grafana at TimescaleDB and write queries against the raw table or the aggregate views. If you are not familiar with Grafana, check out a previous post for a comprehensive example of how to visualize live data.
Here is an example of viewing recent sensor data in Grafana:
Making it public
The project was private while I was still iterating. Before publishing it, I wanted a few things cleaned up:
- A compose file that did not contain my personal entity names
- A documented
.env.exampleto give an example of how to set up the app - CI that runs formatting checks,
go vet,govulncheck, tests with the race detector, and a Docker build - A release workflow that can publish a container image
- Enough tests that I could refactor without guessing
The engine originally depended directly on concrete Home Assistant and storage types. I changed that to use small interfaces so the polling logic could be tested with fakes. That made it much easier to cover filtering, numeric parsing, epsilon behavior, insert failures, fetch failures, concurrent poll protection, and context cancellation.
There were also some practical release fixes. The Dockerfile needed to respect BuildKit’s target platform variables so the multi-arch image would actually contain the right binary for linux/amd64 and linux/arm64. I also learned that the Go version in go.mod matters for CI security checks when actions/setup-go installs exactly that toolchain version. A tiny version bump fixed a failing govulncheck run.
How AI helped
I used AI coding tools on this project, but I did not treat them as autopilot.
I started with a plan from a ChatGPT conversation, then used Codex to review the plan and build the first working version. Claude Code helped with later iterations: change detection, tests, health checks, Prometheus metrics, storage policies, CI, and release workflow cleanup.
Going back and forth with Codex and Claude Code is not the most efficient workflow but I can keep working when I run out of tokens on one of my subscriptions. I’m just one person but if you rely on these tools for work, I recommend picking one and sticking to it.
The most useful pattern was keeping the work in phases:
- Build a small poller that writes numeric Home Assistant states to TimescaleDB.
- Add change detection so unchanged values are skipped.
- Add production behavior like health checks, metrics, graceful shutdown, and minute-aligned polling.
- Add retention, compression, and continuous aggregates.
- Clean up the repo for public use.
I still made the architecture calls. I had to walk back some things that the models added:
- I removed heartbeat rows because Grafana’s fill behavior was good enough.
- I skipped Redis because writing one fresh baseline row after a restart is cheap.
- I kept allowlist and blocklist support together because that fits how Home Assistant entities tend to be named.
That is the part I think is easy to miss with AI tools. The model can write a lot of code quickly, but the owner of the project still needs to decide what is worth building and what is just extra machinery.
Conclusion
If you use Home Assistant and want long term sensor history in a database, the repo is here:
https://github.com/acaylor/hass-poller
Disclaimer: I used an LLM to help create this post. Opinions expressed are likely from me and not the LLM.