Parsing workout data from Hevy on iOS
While I was writing the post about parsing data from the strong app on iOS, I stopped using this app. Now that I have this historical data there are a few approaches but as someone who is busy I ended up using another iOS app that has a native app for the apple watch. It also directly imported all my workout history so stay tuned as I will next be taking a look at any differences in that data.
Fortunately, the script I made is reusable since we are relying on the CSV file to define our columns.
Hevy iOS app
This app directly imported the CSV file from the strong app. Some of the workout names are different and I noticed I lost between 5-10 workouts. Considering there were nearly 900 I think this is an acceptable loss that I do not have time to track down. This new app Hevy has it’s own data export function in the UI. I’m going to download that file and then import it to another sqlite3 database.
Modifying my existing script
Skip this section unless you also used my previous python script to convert the CSV from the strong app on ios to a sqlite database.
In this case I am taking the lazy route and just replacing all references to strong in my python script with a more generic term: workouts. You can use sed to preview the changes if you find and replace all of these matches in the file. Instead of modifying the original file I am writing to a new file.
sed 's/strong/workouts/g' example.py > example_new.pyThis may not work with a macOS or other systems that use bsdtools instead of GNU coreutils. Look up how to use sed interactive replace for your operating system.
If you followed along from my previous post the file is likely named workouts.py.
Now you may check if the new file made the proper edits by comparing it to the original python script.
diff --color example.py example_new.py
12c12
< conn = sqlite3.connect('strong.db')
---
> conn = sqlite3.connect('workouts.db')
40c40
< csv_to_sqlite(args.csv_file, 'strong')
---
> csv_to_sqlite(args.csv_file, 'workouts')Now the script can be executed if there is a CSV file supplied.
Script to convert Hevy CSV file
Here is the script we can use after the edits I made above and welcome if you skipped the last section.
import sqlite3
import pandas as pd
from sqlite3 import Error
import sys
import argparse
# Function to create a connection to the SQLite database
def create_connection():
conn = None;
try:
# Create a new SQLite connection or open an existing one
conn = sqlite3.connect('workouts.db')
print(sqlite3.version)
except Error as e:
print(e)
finally:
if conn:
return conn
# Function to convert CSV to SQLite
def csv_to_sqlite(csv_file, table_name):
# Create connection to the database
conn = create_connection()
# Read CSV file into pandas DataFrame
df = pd.read_csv(csv_file)
# Write DataFrame to SQLite database
df.to_sql(table_name, conn, if_exists='replace', index=False)
# Close the connection
conn.close()
# Create argument parser
parser = argparse.ArgumentParser()
parser.add_argument("csv_file", help="The CSV file to convert")
args = parser.parse_args()
# Call function with supplied CSV file and table name as arguments
csv_to_sqlite(args.csv_file, 'workouts')
You can supply a CSV file with any name to this script to convert it to a new file workouts.db which is a sqlite database. Feel free to name it something else, this script will work on any standard CSV file and simply converts line by line to a SQL database based on the header row (the first row) of the CSV file.
Here is an example of the format of the CSV file that the Hevy app uses:
"title","start_time","end_time","description","exercise_title","superset_id","exercise_notes","set_index","set_type","weight_lbs","reps","distance_miles","duration_seconds","rpe"
"Thursday- Upper Reps","28 Mar 2025, 17:29","28 Mar 2025, 18:52","","Band Pullaparts",,"",0,"normal",,20,,0,
This is the default schema that is created when using that CSV file.
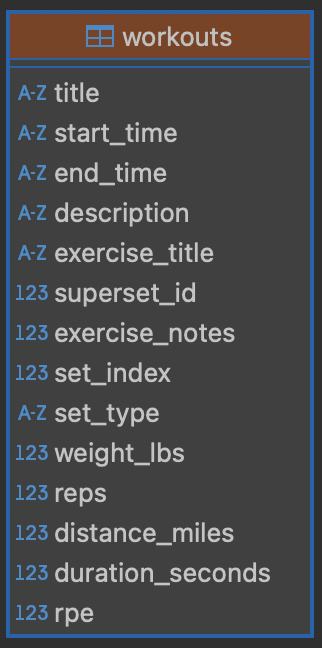
This produced a database with text fields and number fields. Since we know the format of the CSV file we can modify the script to create the sqlite database with more appropriate data types. This will make it easier to query based on dates.
Here is an updated version of the script:
import sqlite3
import pandas as pd
from sqlite3 import Error
import sys
import argparse
# Function to create a connection to the SQLite database
def create_connection():
conn = None
try:
# Create a new SQLite connection or open an existing one
conn = sqlite3.connect('workouts.db')
print("sqlite database version:" + sqlite3.version)
print("connected to database")
except Error as e:
print(e)
finally:
if conn:
return conn
# Function to crate an appropriate database table
def create_table(conn):
# Create the table
conn.execute("""
CREATE TABLE IF NOT EXISTS workouts (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
start_time DATETIME,
end_time DATETIME,
description TEXT,
exercise_title TEXT,
superset_id INTEGER,
exercise_notes TEXT,
set_index INTEGER,
set_type TEXT,
weight_lbs REAL,
reps INTEGER,
distance_miles REAL,
duration_seconds INTEGER,
rpe INTEGER
);
""")
print("Table created successfully")
# Function to convert CSV to SQLite
def csv_to_sqlite(csv_file, table_name):
# Create connection to the database
conn = create_connection()
# Read CSV file into pandas DataFrame
df = pd.read_csv(csv_file, parse_dates=["start_time", "end_time"])
# This assumes that the csv_file has dates in the columns for start_time and end_time
# Convert empty strings to None (NULL in SQL)
df = df.where(pd.notnull(df), None)
# Create the database table
create_table(conn)
# Write DataFrame to SQLite database
df.to_sql(table_name, conn, if_exists='replace', index=False)
# Close the connection
conn.close()
# Create argument parser
parser = argparse.ArgumentParser()
parser.add_argument("csv_file", help="The CSV file to convert")
args = parser.parse_args()
# Call function with supplied CSV file and table name as arguments
csv_to_sqlite(args.csv_file, 'workouts')
print("operation completed")
These data types were selected:
TEXTfor variable-length string data.INTEGERfor whole numbers (reps, set order, IDs, etc.).REALfor measurements with decimals (weight, distance).DATETIMEfor date/time tracking.
Example SQL query to select by year
Here is an example SQL query that will show me all rows from the year 2025. Each row in the database represents one set of a workout routine.
SELECT * FROM workouts WHERE start_time >= '2025-01-01 00:00' ORDER BY end_time;Visualize the data
Now that the data is in a database, there are some popular Python libraries available to interact with structure data in a database. The pandas library will help us load data into memory and there are popular libraries such as seaborn and matplotlib for visualizing the data.
Example of visualization
Here is a script that will take some data from the columns in the database and create some diagrams.
Create a .py file and in this example the sqlite database file will be in the same directory as the python script.
import sqlite3
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Connect to SQLite database
conn = sqlite3.connect("workouts.db")
# Query top 10 exercises by max weight
query = """
SELECT
exercise_title,
MAX(weight_lbs) AS max_weight,
MAX(reps) AS max_reps
FROM workouts
WHERE weight_lbs IS NOT NULL AND reps IS NOT NULL
GROUP BY exercise_title
ORDER BY max_weight DESC
LIMIT 10;
"""
df = pd.read_sql(query, conn)
conn.close()
# Sort values for better visualization
df = df.sort_values(by="max_weight", ascending=True) # Sort for horizontal bars
# Plot max weight (Horizontal Bar Chart with Smaller Font)
plt.figure(figsize=(10, 6))
sns.barplot(y=df["exercise_title"], x=df["max_weight"])
# Adjust font size for labels
plt.xlabel("Max Weight (lbs)", fontsize=12)
plt.ylabel("Exercise", fontsize=12)
plt.title("Top 10 Exercises by Max Weight", fontsize=14)
# Reduce Y-axis label font size
plt.yticks(fontsize=6) # Adjust this value if needed
plt.show()This produces a chart with the top 10 exercises with the highest weight.
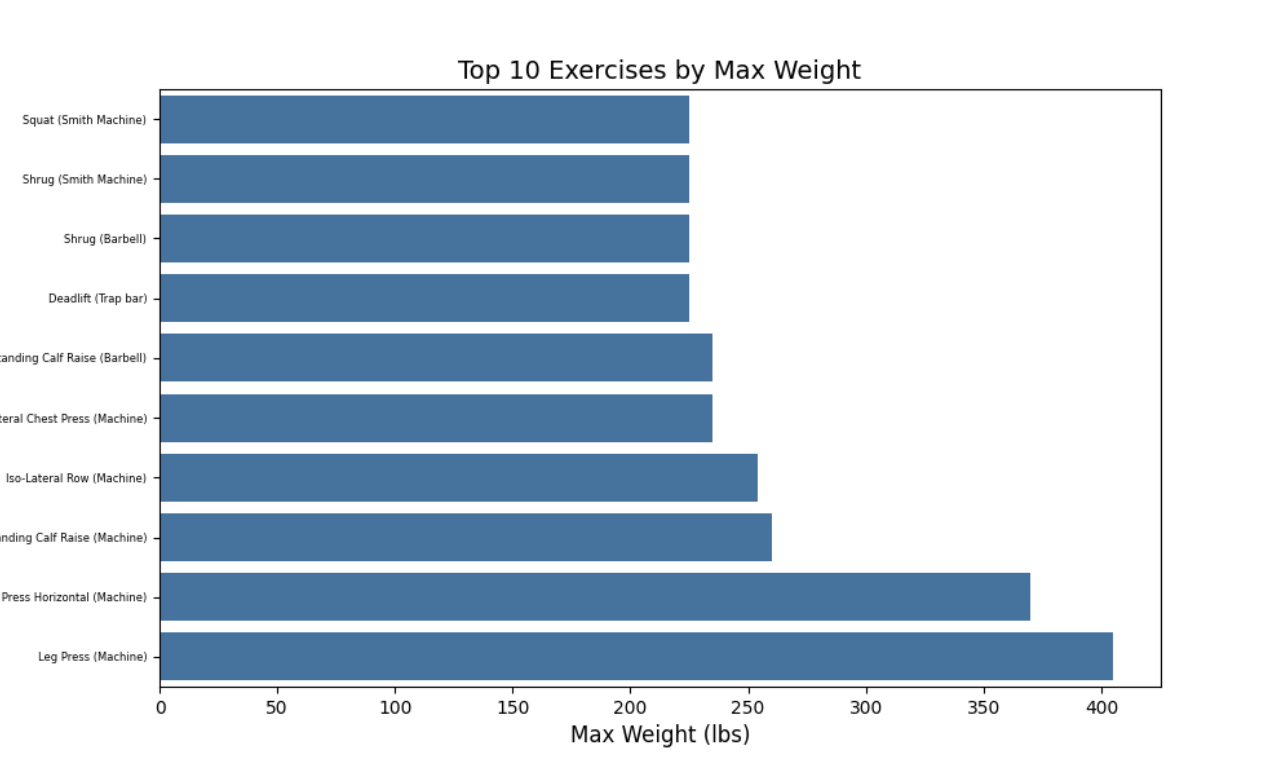
Now with this data in a database, other queries can be made to find information such as the total weight in a workout or a set.