Homelab, 2024 stage 4 Kubernetes
As the foundation of my homelab takes shape, I’m ready to dive into the world of container orchestration with Kubernetes. In this blog post, I’ll outline my experience deploying software applications using Kubernetes, leveraging open-source projects to manage and access software running in the cluster.
Prerequisites
Network
Before deploying any software, I recommend having a Network setup so that computers can communicate with themselves and systems over the Internet. All Kubernetes related computers need to be connected to the same network.
Computers
In order to run Kubernetes, you need one or more computers that are supported by the open source Kubernetes platform. For more background on Kubernetes itself, check out a previous post. These computers can be physical systems or virtual machines.
My cluster will be comprised of a mix of physical systems and virtual machines with different CPU architectures which highlights the flexibility of Kubernetes.
Backup strategy
In order to maintain software over a long period of time, you need to have a backup strategy. Currently I have a limited number of Kubernetes workloads that require backing up beyond the configuration of the applications themselves. Right now my strategy is a cronjob that temporarily shuts down the associated container and creates a tar.gz archive with the current state of the persistent storage. For databases, it is critical that the database server is shut down while you attempt to back up the files otherwise a write operation could corrupt your backup.
DNS
When deploying web applications you will want to set up DNS servers where you can manage DNS records. It is difficult to remember IP addresses and HTTPS encryption almost requires using DNS records to validate the server you connected to is the right one. I currently use 3 replicas of Adguard Home for DNS. Records can be managed in a YAML config file and all changes are replicated between the 3 servers. Check out a previous post for detail on how to set that up.
My cluster
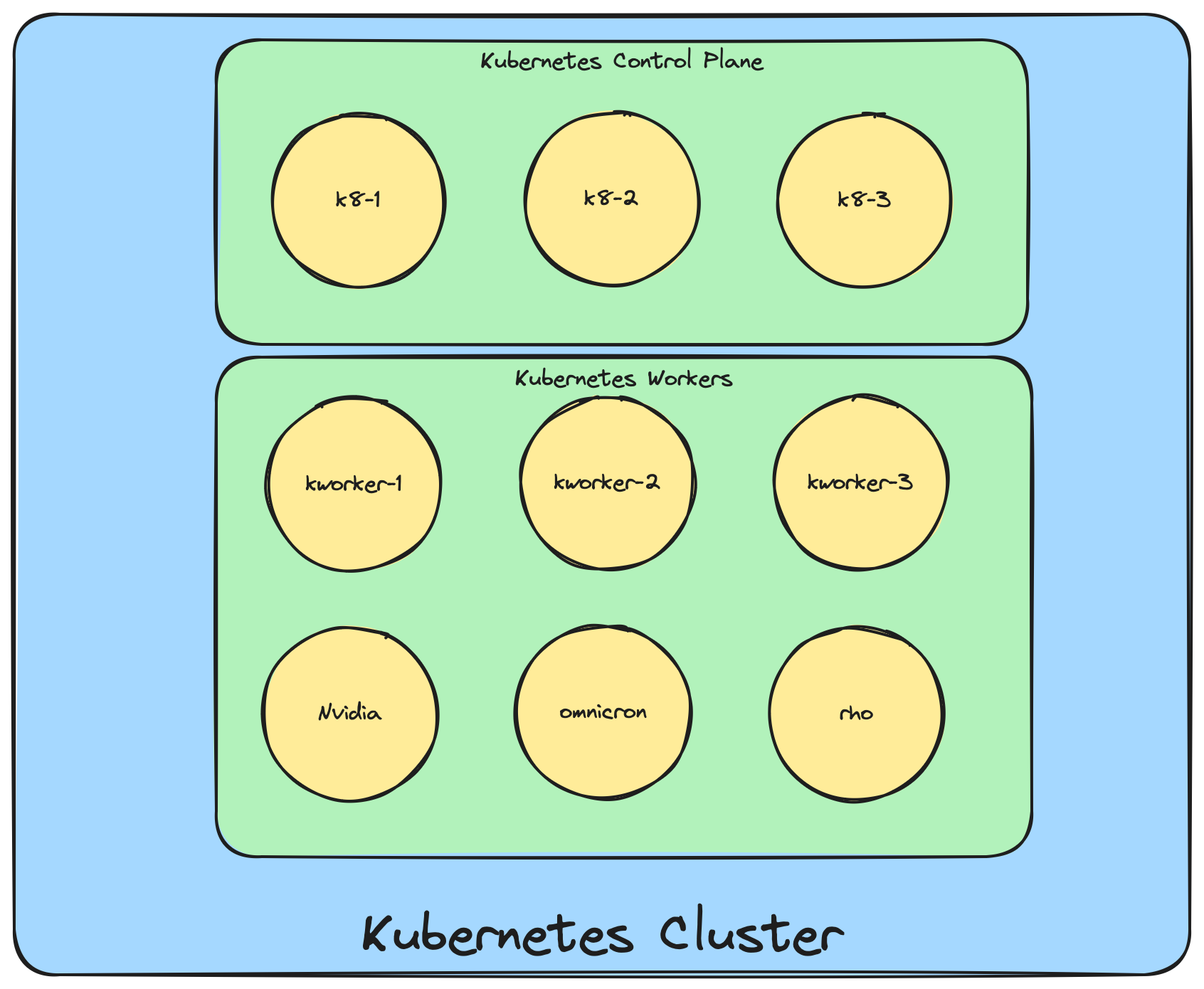
In the Diagram above, the Control Plane is 3 virtual machines. These provide a highly available set of services for the Kubernetes platform to schedule other resources on Kubernetes worker nodes.
Worker nodes in my cluster are 6 computers. 3 virtual, 2 Raspberry Pi 5, and 1 Desktop with a Nvidia GPU.
Managing Software Applications with Kubernetes
To streamline software deployment, I’ve decided to manage all applications from Git repositories. This approach allows me to track changes and automate deployments. With Kubernetes, I can easily scale, update, or roll back applications as needed. This centralized management ensures consistency across the lab, making it easier to maintain and troubleshoot.
Git servers
In order to store Git repositories, I use a few different services.
Public repos
For public repos, I use GitHub and GitLab. This code is free to the public and you are welcome to use it.
For private repos related to my homelab, I use Gitea. Check out a previous post to see how I set that up.
Renovate
To manage code dependencies, I use Renovate bot. Check out a previous post to see how I self-host Renovate. Soon I will convert that to a k8s CronJob. Renovate can open Pull Requests in all three of the Git services that I use to update dependencies.
Deploying Kubernetes with Kubespray
To set up my Kubernetes cluster, I turned to Kubespray, an open-source project that simplifies deployment and configuration. With Kubespray, I was able to quickly spin up a reliable and highly available cluster, ensuring minimal downtime and maximum efficiency. Check out a previous post that I try to keep updated to see how to use Kubespray.
Accessing Software with MetalLB and Nginx
Once the cluster is set up, it’s essential to expose services running in Kubernetes to my network. To achieve this, I used MetalLB, an open-source project that provides load balancing capabilities within Kubernetes. I configure it via Kubespray and it uses a pool of IP addresses on my network to assign to containers running in Kubernetes that have a Load Balancer defined.
Additionally, I configured Nginx as a reverse proxy server to handle incoming traffic and route requests to the correct services. This is configured within Kubespray as the nginx-ingress-controller and you can provision new Reverse proxy entries as Ingress objects in Kubernetes.
Running AI Workloads with GPU Acceleration
As my lab now has “AI” workloads, I added a Kubernetes node with an Nvidia GPU to support hardware acceleration. With this addition, I can now take advantage of the power of GPUs in my Kubernetes cluster. This enables me to run containers that can use GPU acceleration or create my own software apps with libraries like CUDA. I also plan to set up video transcoding services. I plan to create a post regarding this topic soon.
Persistent Storage with NFS Shares and openEBS
To ensure data persistence and availability, I implemented a combination of NFS shares and filesystem volumes managed by openEBS. This approach provides a scalable and fault-tolerant storage solution for my applications, ensuring that data is safely stored and recoverable in case of node failures. I plan to write a post about configuring openEBS, I think I can do it with Kubespray but I set it up after the cluster using Helm charts.
Monitoring Metrics and Logs with Prometheus and Grafana Loki
To gain insights into the performance and behavior of my applications, I set up a dedicated system running Prometheus and Grafana Loki. These open-source projects enable me to collect metrics and logs from Kubernetes applications, providing valuable information for troubleshooting, optimization, and monitoring. In Kubernetes, I use the Helm chart kube-prometheus-stack to collect metrics and send them to my dedicated Prometheus server. I plan to write a post about setting that up soon. I do have a previous post to set up Prometheus and visualize the Metrics using Grafana.
I have a previous post to set up Grafana Loki to collect logs and I will try to keep it updated over time.
I run these services outside Kubernetes because I want to ensure that my solution for observability and troubleshooting my homelab will still likely run even if all of my computers and UPS systems are offline. These all run on a dedicated virtual machine that runs on a low power “micro” desktop system. That is also how I deploy Home Assistant which I plan to post about soon.
Managing Kubernetes software with argoCD
With the combination of Git and argoCD, I deploy my containers by defining their configuration in a Git repository. Then argoCD clones the code in the Git repo and uses that to deploy objects to the Kubernetes cluster. Check out a previous post to see more information about setting up argoCD.